adding the required license texts is an obligation of a developer, so he must take care when using AI generated code.
But LLMs doesn’t simply copy paste from a specific source code fragment, so it’s not the same as taking a code fragment manually …
I used an LLM (Google Gemini, the preview of the Pro model, which is free to use via Google AI Studio) to bring AgX to darktable.
Sometimes, it did copy-paste from sigmoid - but I pretty much asked it to do so, and I would have done the same manually, only much slower, to lift the primaries functionality over to my code.
Other times, I uploaded the source of the UI ‘framework’, plus one or two modules as examples, and asked it to e.g. add the plot of the curve. It did that pretty well, too.
When I asked it to split the UI into tabs, it was unable to do it by itself (Claude failed much worse, though). What worked was, I asked it to summarise the API, and guide me through the implementation instead of providing it. It did not get everything right, but with its guidance and my own observations, I was able to get it to work.
In my experience, literal quoting was only done when it was really needed (primaries), otherwise it adapted / designed code, rather than copying. One issue with Gemini Pro is that it wants to refactor and clean up, which means if you ask it to implement something small, it may end up rearranging all your code. You can specifically ask it to only do what you asked, but then sometimes it takes that too literally, and does not perform changes necessary to get the new code working (e.g. updating some struct that the UI change needs, because I said ‘update the UI but don’t refactor anything else’).
Another problem was its overconfidence: even though I prompted it ‘if you have doubts, don’t start working on an answer; ask questions instead’, it never did that, even when it was uncertain about something (one can display the model thoughts). In a few cases, when the code did not work, it came up with a hypothesis and asked me to add debug prints to the code (I do have lots of debug prints, but those are all mine, so I never explored its suggestions, or what it could have done with the results).
I ended up changing / rewriting pretty much all generated code, but its output provided a pretty good starting point much quicker than copy-pasting would have. And the ‘be a mentor and guide me’ prompt provided a very good experience.
8 Likes
That’s some fascinating insight into your process with LLMs, thank you!
Gemini comes up in google search ahead of actual search results, and for less popular languages, like power shell, the amount of times stuff is obviously copied from a blog post is quite high. In fact the blog post is often in the first five search results.
When it isn’t outright copying, it just makes up what it thinks you want, makes up whole powrshell modules, makes up functions, methods, classes. Pretty annoying and a waste of time.
Hallucinations are there, yes. But in the ‘studio’ (or using the API), the ‘Pro’ model and its 1 million word context allows you to upload the whole UI framework of darktable, plus a few modules as attachment, as reference. It helps a lot. And it’s one of the ‘thinking’ models. I have no idea what the search uses, but that’s certainly something different, as the model I use takes 10 - 30 seconds to respond.
Gemini in google search probably functions differently than a gemini chat. It’s not uncommon for it to quote or give you information from the first websites in the search result since it actively searches through them, a bit like ChatGPT web search mechanism.
Not defending it of course, since it can remove traffic from those sites since the user simply gets their information from the AI.
I am of this idea, perhaps a bit “old school”: when software gives the wrong output, its called a bug.
Which is fine if it attributes the results properly. Does it?
The narrator in the background: It does not
Given how little people actually apply critical thinking lately. Hallucinations are really really bad.
It does. Every statement has the appropriate link:
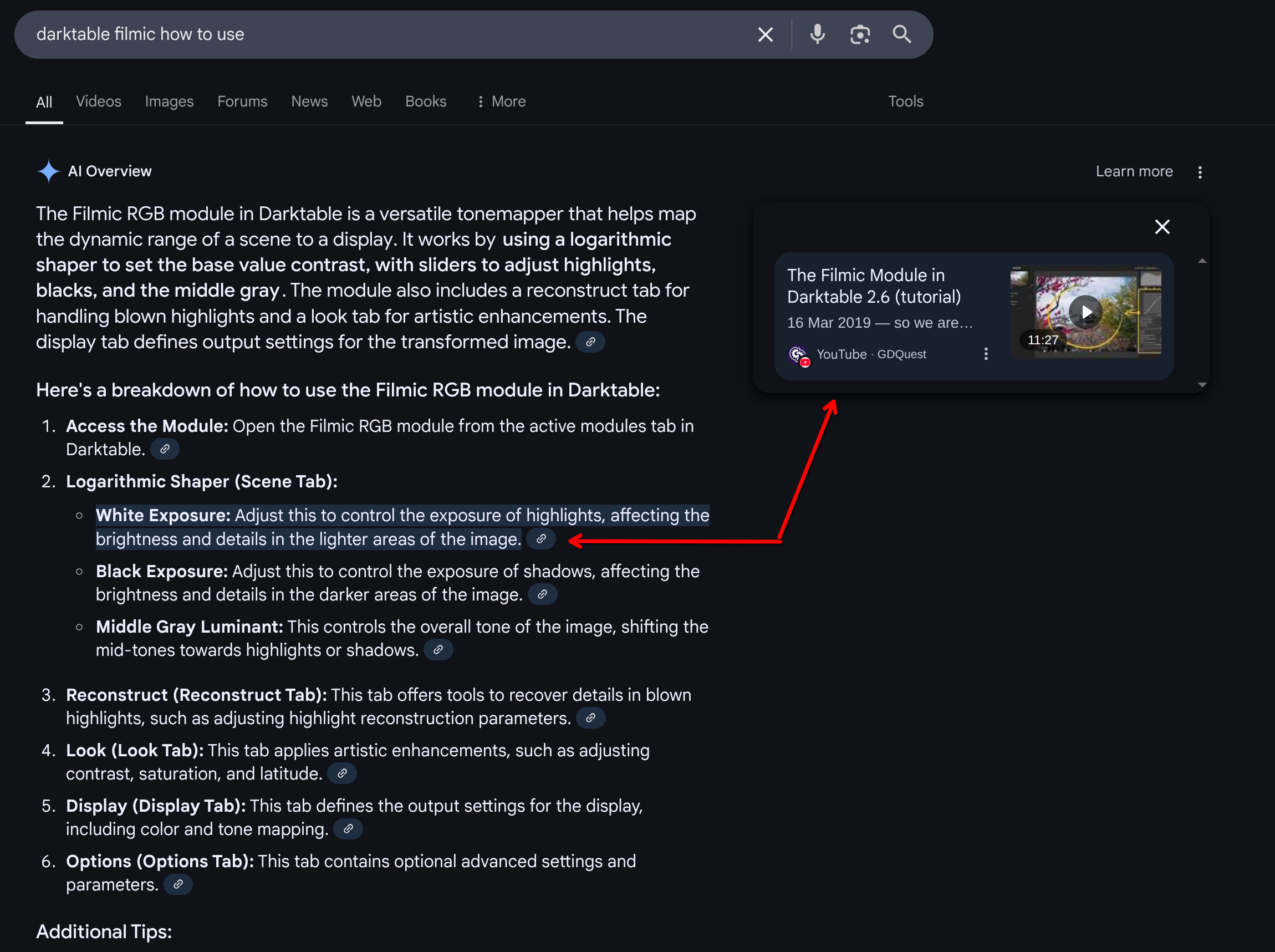
This is also a good example of how it fails/gives bad information. Some of the sources are from darktable 2.6 and are now incorrect or incredibly out of date.
2 Likes
In my experience with powershell: sometimes. My memory has been really bad lately, especially since I haven’t spent a lot of time writing power shell lately, and I end up searching the same thing several times.
Quite a few times I’ve had Gemini put up something without a link that I later find I’m a blog post, but Gemini has changed something inconsequential, like variable names.
2 Likes
It does sometimes fail to understand what it links to, or does not actually use the source in the answer. For example, a friend of mine asked something simple, clear-cut about a phone (if it had a headphone jack, so a yes/no question), was confidently told ‘yes’, with a link to a review… which specifically highlighted that the phone had no headphone jack. So don’t think that only because a source was linked, it was used or used properly.
2 Likes
Fortunately, for code, the compiler will let you know quite firmly if an API does not exist. ![]()
Subtle issues (whether matrices are in row-major or column-major order) may go unnoticed. Like my first LLM-ported agx module variant, which had them the wrong way. ![]() That was slop, clearly.
That was slop, clearly.
1 Like
It does provide sources, but doesn’t necessarily correctly quote those sources. The YouTube channel GamersNexus did a video recently about how the Gemini results were attributing something to GamersNexus that they never actually said.
3 Likes
It’s a really blurred line sometimes between regurgitating and blatant copying. I work in academia and one of the applications I work on revolves around proposals and grants. For some time, Copilot would offer me autocomplete suggestions that clearly had to do with the domain of proposals and grants, but with code, styling, verbiage, and other indicators that made it seem like it was pulling code from someone else’s project and assuming I wanted to do the same thing.
Mechanically it’s not the same as a developer just copying and pasting code directly from a source, but if an LLM “thinks” about an answer for me and just so happens to come up with an answer that is exactly some other source code used in its training, it feels like splitting hairs to say that’s not copying.
It’s gotten a lot better over time, and currently seems to take a lot more of my code’s context into account. But that’s part of the frustration of using LLMs: it’s constantly shifting and being tweaked and behaviors aren’t consistent yet we are also being bombarded with claims that this is the future and we need to get on board or be left in the dust.
3 Likes
it heavily depends on your usage of a llm - if you provide other code as context or use internet search capabilities - then there might be snippets completely taken over. LLMs doesn’t deal with snippets, they deal with tokens and their probability. If he most probable solution is already used somewhere else, it will be hard to arguement any intellectual property at that side ![]()
1 Like
An interesting thought experiment is the following: you start in your favorite IDE with some code, stop in the middle of writing and press Tab (or whatever key is assigned for autocompletion). Should you be allowed to start a pull request for such code? I mean it could just be a copy of something else! At the moment, I still see LLM as autocompletion on steroids. Of course, one issue is the code it learned on, but generally speaking: what makes your “traditional” autocompletion different to a LLM? (Yes, I know it is not that simple and definitely not a black&white answer…)
Another funny story that comes to mind: in a programming course at university we had to implement some graph traversal algorithm. Actually, the algorithm was so simple that you could write it in 3 lines of Java code. Of course, that triggered the plagiarism check because someone else came up with the exact same solution already. So I replaced my for with a while - just to see that someone else had that idea too. My solution was to write two for loops, which iterated over half the graph each …
1 Like
Looks like this plagiarism detector needs some work… ![]()
A good solution would probably be to call a function inside the loop. But I’d warrant it would also get some hits as programmers often call their functions similar things. At least nowadays when you don’t have to save on characters and end up with things like strcpy.
I think it was only this one exercise where it went crazy. I heard that some students, who submitted very early, were able to just rename the variables, but after a while the common space of variables was used up ![]()
Usually, the other assignment required you to write more than 3 LOC, so it wasn’t triggered that easy.
1 Like