thanks for your linear scan! Always fun to try on scans from other people.
Up front: The relation between blue and red (the rocks and the sky) does seem a bit weird. I can convert it and end up with cyan sky, or I try a different white point and end up with ‘better’ sky on first try, but the rocks can be really red. And very contrasty.
Adding a tiny but of curves to raise the shadows a bit, also lowers saturation (brightening reduces saturation) and it seems ‘better’. Still, a lot of warmth on those rocks  .
.
Also, I do notice something of a limited dynamic range. Not only by looking at the histogram of your linear file, but also when pulling and pushing and working on it, it tends to become noisy if you’re not careful.
I feel your scanner should perform better with the gain raised a bit to maximize DR for your scanner, and I suspect calibration the ‘scan as positive’ with a real it8 slide target may yield interesting results, because something seemed off in your blue/red ratios. Maybe they weren’t all at the same value?
Setting ‘working space’ in Photoshop is always a big no-no to me. It doesn’t really do that much if your files are tagged with a working space, and it seems to confuse people who tend to think it yields better results.
My scans are ‘tagged’ with the profile from calibration. That is converted to rec2020-linear and that’s where I work in. In the end I convert the result to whatever I want for output (mostly sRGB or the profile of my printer).
In your settings yo have ‘blend layers in 1.0 gamma’ enabled. That’s not bad at all, but it’s not the default. Just wanted to point that out :).
whitepoint set on the brightest point in the sky, yielding better sky colors in this case I think.
lce-conversion-example-try1.tif (16.7 MB)
whitepoint set on the brightest point in the picture, which seems to be a specular highlight on one of the rocks.
lce-conversion-example-try2.tif (16.7 MB)
I like to have the ‘reciprocal’ in the method, so I want to do a 1/r 1/g 1/b or something in there.
Working in 16bit Photoshop or 16bit Affinity Photo I switch it around a bit. I find the darkest point in the scan (so what will become our whitepoint in the image). I fill a layer with that color, then place the scan-layer on top of that with the ‘divide’ blend mode. That inverts the picture while having your white point set. After that we still have to set the blackpoint (but you have a bit of filmstrip in your scan for that!). This seems to work better while gamma-corrected. So I apply a dirty levels layer to push the gamma up by +/- 2.2 (a power of 0.45471). Then I add another levels layer and use the black-picker and click on a bit of filmstrip. Or - Affinity Photo ahem, - I add a permanent color-picker on the filmstrip and I adjust black-levels of the R, G and B channels up manually till the filmstrip reads 0,0,0 as values.
‘Basically’ I’m there. In the try1 version I added a little curves to boost the shadows, int he try2 version I did nothing. I used 563/256 = 2.199 gamma now which is the AdobeRGB gamma, but you can adjust it too taste. Or - in my case - the scan images are tagged with a linear ICC profile, so Photoshop and Affinity Photo already display it correctly without having to do a gamma adjustment myself.
I start just like you, with a linear file and while working I add a gaussian-blur (+/- 6px). This removes sample-errors from grain / noise / weird pixels. Using a live-layer or something helps, so you can just ‘turn it off’ in the end.
I add a threshold layer on top, and I set almost as low as it goes. I use this for finding … well, thresholds.
I slowly move the threshold slider up, till black spots start appearing in the image. I ignore parts of your film-leader, we’re only interested in the ‘real image content’. In ‘try2’ I picked this point, the highlight of the rock:
In try1 I used this, in the sky (hoping it would be a white cloud):
I then sample that point (with the threshold of ofcourse). Either sample with the blur layer working, or pick an average 3x3 or 5x5 picker to average it out.
Now, we’re going to create a solid-color fill layer with that selected color, and put it under the scan. We take this color, and divide it by your scan, not the other way around.

Red layer is the new fill solid, with the solid sampled color. Green is your original scanned image, and we set the blend mode of it to ‘divide’.
This already gets us a lot of the way:

I add a levels layer, and give it a gamma correction of +/- 2.2 (depends on the software if you need to enter ‘2.2’ or you need to enter the value of ‘1/2.2’. It should be brighter .
Then I create another levels layer, and adjust the individual channels so that the filmstrip becomes pure black. I need to add a color-sampler to it and watch the values manually:

This yields me the result of ‘try2’:
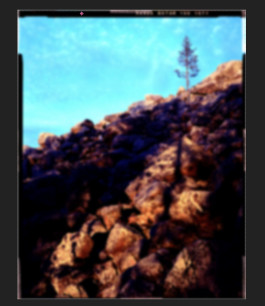
Turn off the gaussian blur, and you can tweak it further. This is my ‘start’.
In Affinity Photo I can actually do this all in 32bit mode, so I never clip anything. After setting all my thresholds and points, I can always take a levels layer and lower the whitepoint to recover information that might look clipped. This makes setting the whitepoint pure relevant for ‘starting exposure’ and ‘white-color-balance’. So I can try different points to see what color they give, and always lower the exposure again to get everything outside of clipping ranges.
As a trick I learned from @rom9 somewhere in this thread, you can look at the median of ‘the whole resulting image’ (all channels combined), and then add a levels layer, and adjust the gamma of the channels individually till the median of that channel matches the overal median. I think Photoshop has it the histogram view. I know Affinity Photo has it - a bit buggy though.
In try2, that gives me this, a try2b - still the sky is cyan though:

I couldn’t resist and had to try the ‘median color balance’ thing on the ‘try1’ version as well. It turned the blueish sky back to cyan a bit  . But it did nice things to the rocks though (not as neutral as previous, but not overly red).
. But it did nice things to the rocks though (not as neutral as previous, but not overly red).

Now, normally I have my own programs to do this in batch. The method I use then is a bit different, but it’s the order of the calculations that’s different, the principle still is the same.
I divide the film color by the scan. That gives me values who start at full clipping white and go up. You can’t do this in Photoshop, you need a good 32bit / HDR workflow for this. Subtracting ‘full white’ from it gives me an image that starts at full black (and the filmstrip should be full black) but goes up into very hard clipping levels. I then scale the whole thing with one big multiplication back into 0.0 - 1.0 range (so nothing clips). Then I look at histogram-binning per channel to set the whitepoint. Since I’m working in HDR, I can be quite aggressive with my percent-thresholding here, because nothing will be truely clipped.
I then do the median-color balance thing (or not, or at 50%…) and can think about saving the file. I can bring everything back into non-clipping ranges and write it as a 16bit TIF file, but it would require some exposure fixes (since I lowered exposure to prevent clipping). Or I save it as a 32bit floating-point tif file, or - even more to my liking - a PIZ-compressed EXR file. Those EXR files open in Darktable, where I can mess with filmic or other tools to map the dynamic range into display-ranges.
The thing here, is that I merge all scans from an entire roll into one big mosaic, of 512x512 squashed images with absolutely no spacing or other pixels in between (and no filmleaders, or sprockets, or whatever). This helps setting the blackpoint/whitepoint And median color balance for the whole roll of film in one analysis. This helps me to disregard outliers in weird scans or pictures. Those auto-tools work really well when you use them on 36 pictures of the same film at the same time (imagemagick’s magick montage is golden here).
In the end I get a bunch of values, which I can enter into an imagemagick commandline to process the individual scans at full resolution.
I’ve been learning g’mic lately and have functions and filters now that do the same thing in g’mic.
I’ve written the tool in c++ as well using libvips that does the whole ‘making montage and analyzing’ thing on a glob pattern of files, and then processes those files with the settings discovered. This automates it pretty well. But it’s harder to experiment with methods so the c++ tool didn’t see much love lately.









 ) by using a simple 1-i invert, I still think you have to use a 1/i somewhere.
) by using a simple 1-i invert, I still think you have to use a 1/i somewhere.




