This mask manager setting is quite shy. To see it, you must have your stylus hooked up and working, and the brush icon next to the gradient icon must be lit up. Then if you make sure you’re scrolled down in MM you should see it.
1 Like
I can confirm that even a path with 10 nodes and some feathering is enough to send the fan of an M4 Pro full throttle. Not rven video encoding manages to do that.
1 Like
It’s perhaps obvious but worth saying - a quick test suggests to me there’s no speed difference between stylus vs. ordinary mouse when brushing.
Exposure - I’m thinking put the mask in the actual module where needed (higher up the pipe) rather than via exposure (lots of re-calc).
1 Like
That’s weird, I use paths and brushes quite often, and never noticed much of a slowdown (nor fans, but the Mac Studio doesn’t ever fan). Always with feathering and blurring, too.
1 Like
I can confirm that.
That’s definitely a solution that improves things somewhat. To me, however, it looks like a fundamental problem.
Here’s an example with exposure.1 using a relatively simple drawn mask with feathering.
Orange indicates all transfers between CPU <-> GPU or copy and buffer operations.
If you look at how fast normal exposure without a mask takes…
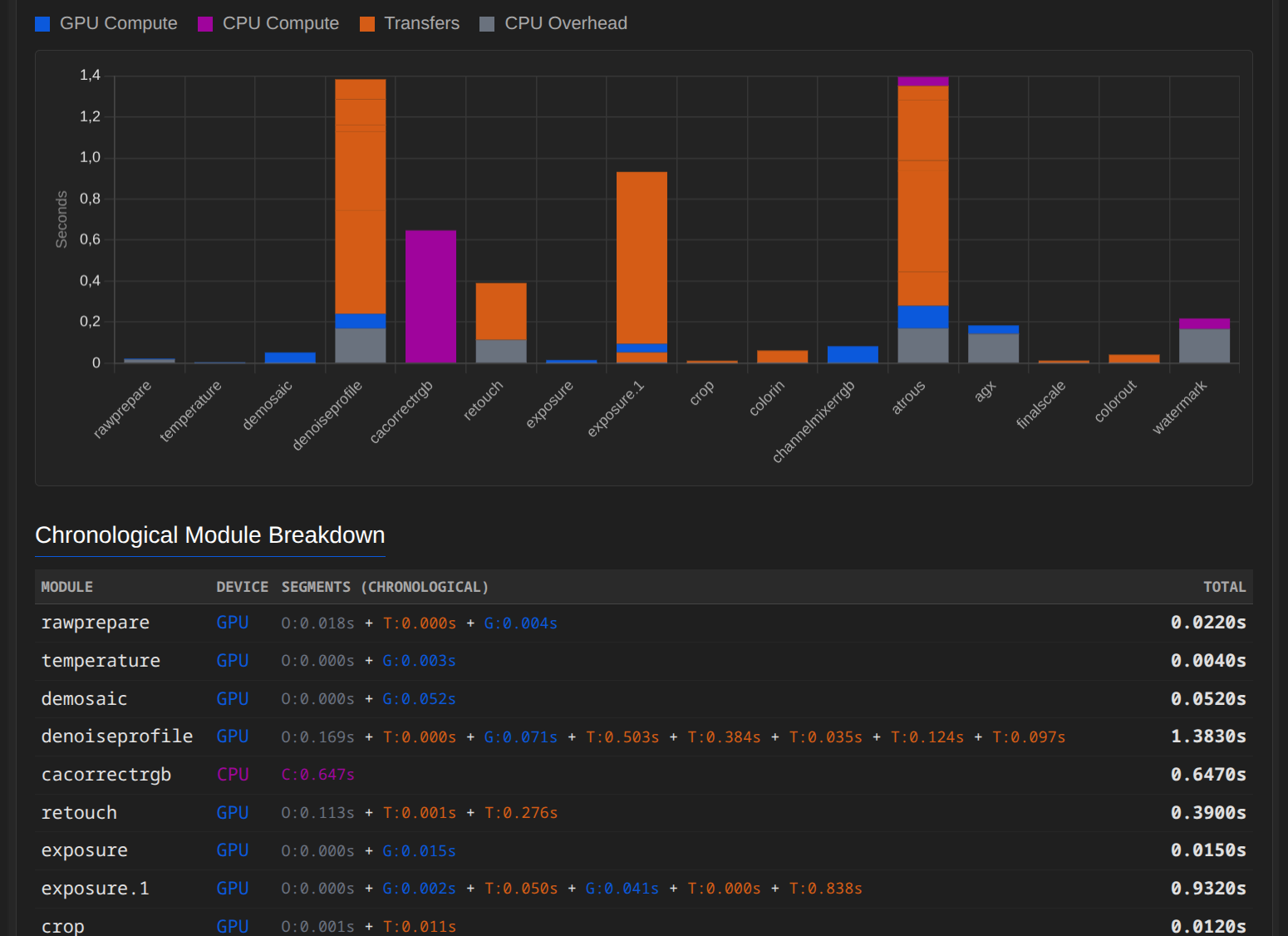
As soon as the GPU only has to “work”, everything happens very quickly. I’m no expert, but if brush and path are each prepared by the CPU and then sent back to the GPU, then a lot of copying goes on.
2 Likes
I’ve already been thinking a Request For Comments (RFC doc) in github would be a way to go. I’d be asking how much work is it to support stylus angle, i.e. map it like pressure (assuming even possible). Make clear I appreciate this might be a very minority user benefit. And take it from there. Maybe a dev might take it on as light relief from GTK4! Maybe actively look for a third party/person to do it.
What else might you like to see included? Can be a joint effort.
1 Like
There is definitely some messed up logic going on there. Another example is zooming while moving the mask. It seems like there are certain actions which will trigger a pipeline re-process, but instead of having a programmed delay to see if the user will still execute another action, it just keeps triggering over and over again.
- Moving one point: does not trigger updates
- Moving the mask such as a single point is an anchor: triggers updates
- Increasing size with scroll: triggers updates
- Moving the mask: does not trigger updates
Looks a bit messed up but maybe this behavior is documented somewhere. What is strange is that even with the mask not moving, changing any module’s value prior to it is insanely slow
2 Likes
@Jens-Hanno_Schwalm , you’re an expert on pipe workings and efficiency. This thread is principally about responsiveness when drawing a mask with a brush. A couple of posts above there’s data showing lots of cpu-gpu transfers (exposure.1). Whereas just above that, Bastian finds his Mac Studio performs relatively well. Do you think there might be scope to speed things up? This could perhaps transform the use of pen and tablet in DT!
1 Like
Are you using HQ processing?
I’ve done dodging and burning (low opacity, lots of strokes) with a brush on a 7th Gen i7 with a 1060 GPU without any lag.
If you have a lot of modules enabled (or some heavy hitters) and you are editing a mask early in the pipe then I could see a slowdown because the preview keeps updating while the mask (and it’s effect) is applied.
1 Like
I’m pretty sure it would be a LOT of work. It’s probably a better candidate for GTK4 than GTK3, since GTK4 may handle it better.
This would also probably be highly OS/driver dependent so considering that we have no Windows developers and very few Mac developers I’m not sure we could even do it.
1 Like
This happens to me even in a 1000px wide window with HQ processing disabled. 5950x and RTX3080 10GB.
There’s definitely something funky going on there with the massive pipeline process going on every time there is a change to the size of the mask
2 Likes
I principally don’t see any bottleneck with mem transfer.
What we do not have - and that’s the slowing-down thingy - is an OpenCL code part for 3 module-specific functions we rely on for masks.
distort_transform() distort_backtransform() distort_mask()
Those are the bottlenecks and we are aware of that. If we want to improve mask processing via OpenCL, that would be the part to start working on.
5 Likes
Thanks
Ok thanks, I’ll not do an RFC.
1 Like
Thank you for your reply and clarification.
With appropriate abstractions the implementation could be generic, but with a back-end added if and when devs were available for each platform.
1 Like
I could live with the current implementation of the pressure stages quite well, thank you again for the instructions.
That would be the important part for me at the moment. I’m not sure how “we” can help there, but I’m currently looking at the C code. How good are your C skills?
How are your C skills?
Non existent. I can of course read C but I cannot write it or really keep a mental model of what is going on. I only know C#, Rust, a bit of Go, JS, Python, SQL, and a few bits and bobs of other languages. ![]()
Zero I’m afraid!