This has been on my mind for a while, but recent discussions prodded me to throw the idea out there to see if it sparks anything.
If I were developing a new raw processor (how I wish I had the time!), I would try to implement a plugin architecture. Basically, a plugin takes as input image data (in some format, encoding, color space, etc) and a mask, and it outputs a new set of image data.
In addition, plugins could be written in different languages (Python, Julia, Rust, etc); this allows for quick testing of new ideas and opens up development to people who don’t know C++.
Benefits:
Anyone can develop a plugin and publish it. There’s no need to decide which ones go into the canonical set of modules of any given program.
Knowledgeable people can still review and recommend sets of plugins and workflows.
Photographers pick and choose the best set of plugins to develop a given picture.
There would be no need, for example, for Carlo to re-implement sharpening or noise reduction in Filmulator – in fact, Filmulator could be just a set of plugins that are compatible with already existing plugins. The same for capture sharpening, etc.
I think this approach would lead to a large and vibrant ecosystem of plugins and would result in much better tools. New ideas could be easily and quickly tested, etc.
Last but not least, this would help breaking the monolithic approach necessary for the current generation of raw developers, by making it possible to separate the UI from the processing.
Of course the challenges are not trivial. Without writing a single line of code I can see:
Developing the specification for the plugin input and output formats will require work and experimentation.
Sometimes processing is not a linear, independent sequence of steps (e.g. distortion correction requires the raw data), potentially leading to “hacky” cross-plugin coupling.
Each plugin must also be able to specify its user interface somehow.
How to specify masks?
While difficult, I think all of these challenges have clean technical solutions.
In this utopian future, I see UI developers working on amazing, fast interfaces that integrate any number of plugins, which each photographer picks and chooses according to their needs and preferences. There’s plenty of room for different approaches to coexist. People implement new and innovative plugins all the time and the community puts them to the test.
This is just a glimpse of an idea; I hope it inspires someone. If not, whenever I find myself less busy than I am now, I might follow in Glenn’s footsteps and implement it myself…
Gmic is kind of a plugin collection. Since this approach has no concern for workflow and pipeline consistency, it’s terrible for productivity, because each plugin is standalone and doesn’t care about the rest of the pipe.
Image processing is a pipeline, in which operations matter as much as the order in which they are applied.
I don’t think that’s a fair assessment of g’mic; you could say it has a plugin collection available in the GUI plugin. It’s a language really, with various interfaces.
I agree plugins are not a good fit for raw processing in general, because separation would be impossible for certain parts. I think it works better at the post processing (artistic) stage.
Edit: I’ll just add that I’ve literally used g’mic language in a raw pipeline myself thanks to rawproc. It’s ideal for quickly prototyping a concept. G’mic can handle images in a pipeline itself, so there’s no difficulty with that. The problem arrives when you need metadata from another step which has not been exposed.
Right – a framework to put together a set of sensible workflows (pipelines) is necessary. I’m sure the monolithic approach is not the best solution, though.
Anyway you are defining the desired solution before even stating the problem you want so solve, so that will be another typical moment of FLOSS with nothing usable at the end.
Fair enough. The main problem I’d like to see solved is this:
Allow the integration of new processing algorithms into a pipeline, without requiring a specific programming language nor acceptance of the implementation into a monolithic repository or application.
I think this would contribute to a healthy, innovative and productive community and ecosystem. Examples of things this would enable:
Users could experiment with new ideas and algorithms and share their implementations without having to go through the onerous process of getting their code accepted by RT/DT.
With well-defined interfaces, developers could focus on their main strengths and develop specific plugins, without the heavy burden of maintaining a full application.
Users could select their favorite plugins: one could, for example, use capture sharpening, develop with filmulator, map with filmic, and output with sharpen after resize. No existing application can do all these; the implementations exist but each in their own silo.
Other problems I’d like to see solved:
Eliminate C++ as a requirement. Allowing Python, Julia, Rust, etc, would expand the pool of potential developers and speed of development.
Decouple the UI from the pipeline. This would allow faster innovation in the UI design.
Anyway, as I said at the beginning, I’m just throwing this out there to see if it causes any ripples. If it doesn’t and it just sinks, well, someday I may prove you wrong, or maybe not.
Continuing just throwing ideas out there, I thought I might show an example of a large application that has some of the properties I’ve described for my utopian raw developer, from my own field (communications and signal processing). This might help clarify what I mean.
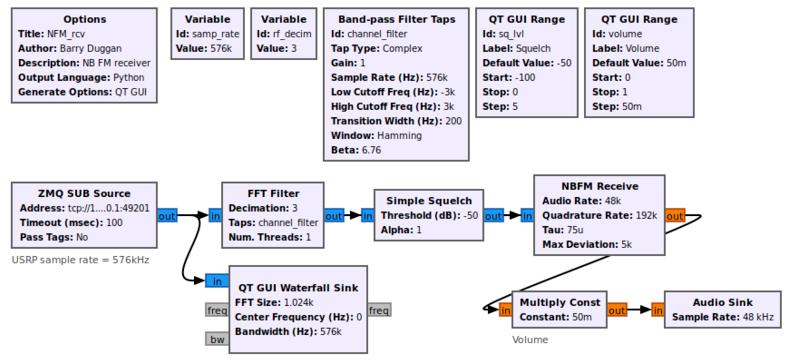
In communications, we have an input signal, which is then processed by a pipeline (we call it a flowgraph), and an output signal is produced at the end. One of the main applications for building and running pipelines is gnuradio (https://www.gnuradio.org/). It is a library of processing blocks (what I’ve been referring to as plugins), which are connected as a pipeline and executed. A simple example would look like this (this is an FM receiver):
The user “draws” this pipeline, and then gnuradio writes high-performance code to execute it. Each block may run on a CPU, GPU, or even in an FPGA. Also:
Each block (plugin) performs a single, well defined signal processing task. The interfaces between blocks are also well defined and documented.
Each block may be written in Python or C++.
gnuradio comes with a large set of standard blocks, but anyone can implement a new block and share it with the world. These so-called out-of-tree blocks behave just like native blocks and there is no friction at all when using them.
This last point is quite important, since it allows anyone (from students to experts) to implement something on their own and use it within the very powerful gnuradio framework. It also allows developers with knowledge in specific areas to implement and share new algorithms.
Obviously, I’m not saying this can be directly translated to image processing (which in many ways is more difficult). This is just an example of a successful application that uses some of the ideas I’ve described.
The problem I see is anything but C will produces slow code, and Python is mostly just used to bind C libs to scripting interfaces.
Then, how do you handle IEEE floating arithmetic discrepancies across languages : how do you treat NaN, Inf, what is the expected output of fmaxf(0, Inf) or fmaxf(0, NaN) ? Each language does its own cuisine here.
This is very far from reality. G’MIC was originally designed specifically to write complete image processing pipelines.
This was even the primary purpose of its creation.
The thing called G’MIC in my computer is a Krita/Gimp plugin browser that provides a list of image processing plugins and lets me apply things like deconvolution on display-referred images without complaining. Which means there is no introspection in there and the plugin browser should have been called “browser”.
Anyway, a tool “to write complete image processing pipelines” that doesn’t do GPU is probably good enough to process Lena. Unfortunately, your typical DSLR now outputs 45 Mpx and still counting.
I see a lot of misunderstanding on what is G’MIC here…
First, let’s be a bit more precise:
G'MIC is the name of the script language dedicated to the writing of image processing pipelines.
gmic is the CLI tool that can be used to run those pipelines from the command line.
G'MIC-Qt is the name of the Qt-based plug-in available for GIMP, Krita, PS, Paint.NET, … , that offers a list of pre-made pipelines (filters). You can still write your own G’MIC pipelines there, using filter Various / Custom Code, if you want.
About display-referred images: G’MIC actually does not care about the meaning of the input image values. It just read input images as 1D/2D or 3D arrays of float values. This means you can process any kind of input images. Feed it with scene-referred data if you wish.
About GPUs: Using GPUs is great when the entire image processing pipeline can be computed entirely in GPU. This is actually what you said in the ‘future of darktable’ thread, mentioning the issues of memory transfers when it’s not the case (I agree with you).
As this constraint cannot be met for a general-purpose tool as G’MIC, we opted indeed for a multi-core CPU parallelization (using OpenMP). Not perfect, but generic enough and reasonably fast (yes, I have a 24-core PC at the lab). Real-time is definitely not my goal.
It seems a lot of people can cope with that too (they use G’MIC for processing images that are even larger than 45Mpx).
Take this information as you wish, I’ll stop here for myself.
Cheers,
i also like modularity. you can tell by looking at darktable’s architecture i think. the processing modules are in a way separated such that you can easily add and delete them. unfortunately they are not easy to create and hopelessly entangled with gui code. also the interface isn’t super general and doesn’t allow for graph processing, just a linear list.
in vkdt, there is a module interface too. it’s based on a node graph though, so you can connect the same output to multiple inputs (see the arrow connections on the right):
and these module graphs are further decomposed into a more fine grained node graph (sorry can’t see it if you’re on a dark theme due to transparency):
and the interface is much simpler, gui code is completely out of the loop, and modules can be created by just some text files describing the kind of inputs and outputs plus the actual processing code, see this simple example:
so. in a way most of what you’re asking we always had in a form or another (i suppose natron modules are similar).
what has not worked well in the past though is
different languages (dt: sse/opencl/i386) introduce a lot of mainenance overhead
processing history compatibility guarantees with 3rd party modules is not really possible
high performance using a mixture of languages does not work (even c+opencl is a problem due to all the copying!)
and really, i don’t understand how you would put down the one liner exposure compensation in the above example in more simple terms in any language. given that you can just copy/paste the 25 boilerplate code lines, what’s the difference.
so i think allowing everyone to write modules in any language will give you a neat toy for rapid prototyping, but i’d expect it to grow into an unmaintainable zoo of scripts and clutches between them, like packages in the latex ecosystem. if you care about shipping a coherent package with some minimum standards when it comes to code quality and performance as well as backwards compatibility you’ll probably want to keep all supported modules in one single place.
I think the hard part in image processing is not the programming language but the image processing. Image processing and colour is hard, it doesn’t get easier in JavaScript or Python.
Right, I think the next order of business is to state the scope of the solution and the intended audience. Because sentences like
frighten me.
The fact that a bunch of geeks armed with i9 can make the solution work and find the runtimes acceptable to edit a couple of pics each week with no real pressure to deliver a result is by no means a proof of usability in a production context.
Spend a week with a commercial/wedding photographer who has to work 2, sometimes 3, jobs to join both ends and spits roughly a third of their income in taxes & social insurances, and another third in various fees, you will understand what “precariat” means and where the tolerance level toward speed and efficiency lies.
Photography as a business is getting more and more precarious as customers are less and less willing to pay for it, while still expecting state-of-the-art results.
That’s interesting; I have the opposite emotion. That G’MIC allows for a wide variety of use cases IMHO makes it one of the best case studies for a plugin architecture. I think it represents a realization of a lot of the trades to be considered, from extensibility to efficiency. Just because it’s probably not the best tool for processing weddings really points to the implications of those trades.
No. But nobody sad that G’MIC is a tool for photographers doing mass editing. G’MIC is an tool for and from researchers, that is even usable for other use cases.
Agree, but on a lower level I think there’s utility in studying such scripting tools as infrastructure. I think it’s interesting that G’MIC at its origin is a scripting tool, but the majority of its users, in GIMP, have no idea of that.
Disclaimer: I never really used the admin privileges on this website so please don’t treat my comment as that of a Pixls admin.
It’s a great idea. I mean, if I were building my own raw processor I’d be a fool not to — every once in a while — track what everyone else is doing and what great algos I can legally reuse.
Would I give this to a real photographer? Not really, no.
If you don’t actively manage your product/project and instead rely on the “vibrant ecosystem” and on trusting users to build custom per-picture pipelines, you easily get to a place where:
the saturation slider and the color temperature / tint sliders are in entirely different parts of the UI
you have to spend half an hour setting up quick task panel to have simple access to the most used controls
you have to patiently construct a basic pipeline that gives you a sensible output
So a question I would ask is what problem are you actually suggesting to solve and for what demographic.
Is it tinkerers who have the luxury of tweaking one photo for hours on end? Sure, I can totally see these users taking a lazy Sunday afternoon to compare three or four implementations of a denoiser.
Is it for people who have maybe an hour at best to sift through an entire photo shoot and then another hour or two to quickly edit the good shots, send them for exporting and go charge the batteries and prepare for the next shoot while their TIFFs/JPEGs are being spat out one by one? You’ll find it difficult to grab their attention.
If you want this dream project to have maximum impact for professionals, I do genuinely believe that you should aim at giving these people the gift of the only resource that cannot replenish: time.


{kind=link}