Here I’m back on this topic, with “something”.
Basically, the idea is to replace the OpenMP threads by pthreads, which are affected to a “type”; current types are default, read, compute (and maybe “idle”, later, if this PoC is convincing enough).
Default mimics the standard behavior, where each thread is reading one image and registering it.
“Read” threads only focus on reading sequences. While “compute” are today affected to registration.
Well, this is only working with KOMBAT registration for now, but I think I could be adapted later. Still depending on benefits: the global algorithm is more complex, which will be something to consider.
Here’s current interface:
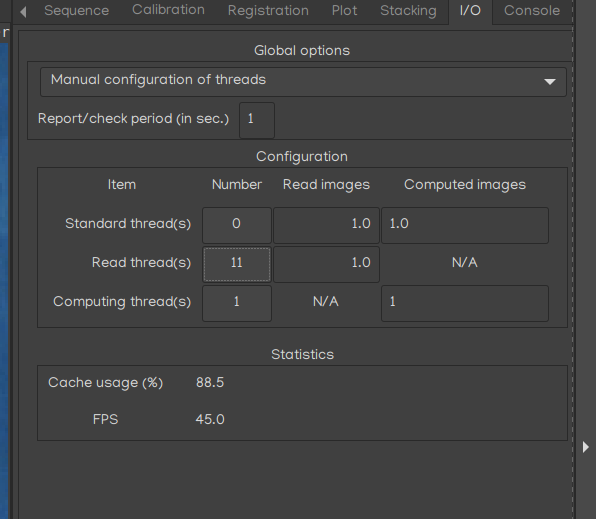
We could then choose among various profiles; here, a “manual configuration” is defined. I’ve did an automatic one, but it’s not taking all parameters for now. Indeed, for each type default/read/comp, we can define:
- the number of related threads,
- the number of images read at each execution (eg. 1.25, means “read at least on image”, then read 1 more image - 25% of time),
- the number of images to be computed (same logic).
A “cache” for images waiting to be handled has been set up.
In manual mode, user can drag’n’drop threads from first column “Number”, to affect change one thread’s type.
Goal is to control efficiently I/O usage to that it matches disk sub-system, preventing overheads, and, hopefully giving a performance bonus.
For now, I can get a 5% boost vs 1.2.0-beta3, but I guess my SSD has already quite optimized flows. I’ll run more tests soon.
Also, I didn’t commit for now 'cause I didn’t re-organized the code, and I’d need more time to focus on testing and validate this approach (well at least on all my hardware).
I’ll keep you informed.
