Hi, is the Richardson–Lucy algorithm in RawTherapee applied to the linear image data, or the gamma-corrected data? I was looking at the code and it seemed the latter, but probably I was making a mistake, since this seems suboptimal.
Thanks!
Hi, is the Richardson–Lucy algorithm in RawTherapee applied to the linear image data, or the gamma-corrected data? I was looking at the code and it seemed the latter, but probably I was making a mistake, since this seems suboptimal.
Thanks!
It’s applied to the LAB L channel
Thanks. According to this reference, the L channel is gamma-corrected, assuming the profile in RT works the same as in Krita.
Over at Luminous Landscape, a post identified some artifacting from another R–L implementation that is likely due the gamma correction So it got me wondering about it. Are there any raw captures of a star chart online that I could use to test for artifacting in the RT algorithm, to see if the same issue appears?
Also, is there any good reason to do it on the L channel instead of a “linearized” L channel? The latter comports better with the Poisson noise model used in Richardson’s original paper, which seems to suggest it should be done in a linear space.
Thanks for all your wondering work on this software. It’s a great vehicle to learn about image processing.
Maybe from here?
Thanks! So, just thinking out loud, would the following be a valid test? (I’m assuming the tone curve is applied before the deconvolution. Is this correct?)
Image A: Demosaic the file in RT. Apply the standard tone curve. Apply R–L deconvolution on the star chart in RT. Export as .tiff.
Image B: Demosaic the file in RT. Apply the linear tone curve. Apply R–L deconvolution. Export as .tiff. Open the .tiff. Apply the standard tone curve. Export as .tiff.
Then compare results? I could also try other images, of course.
Yes, deconvolution (and also other sharpening methods) is one of the last steps (maybe even the very last step) before resizing (if resizing is enabled).
As base for a comparison I would use neutral profile + R-L deconvolution
Sounds good! I am incredibly jet lagged but will test soon. Thanks for letting me bounce ideas off you.
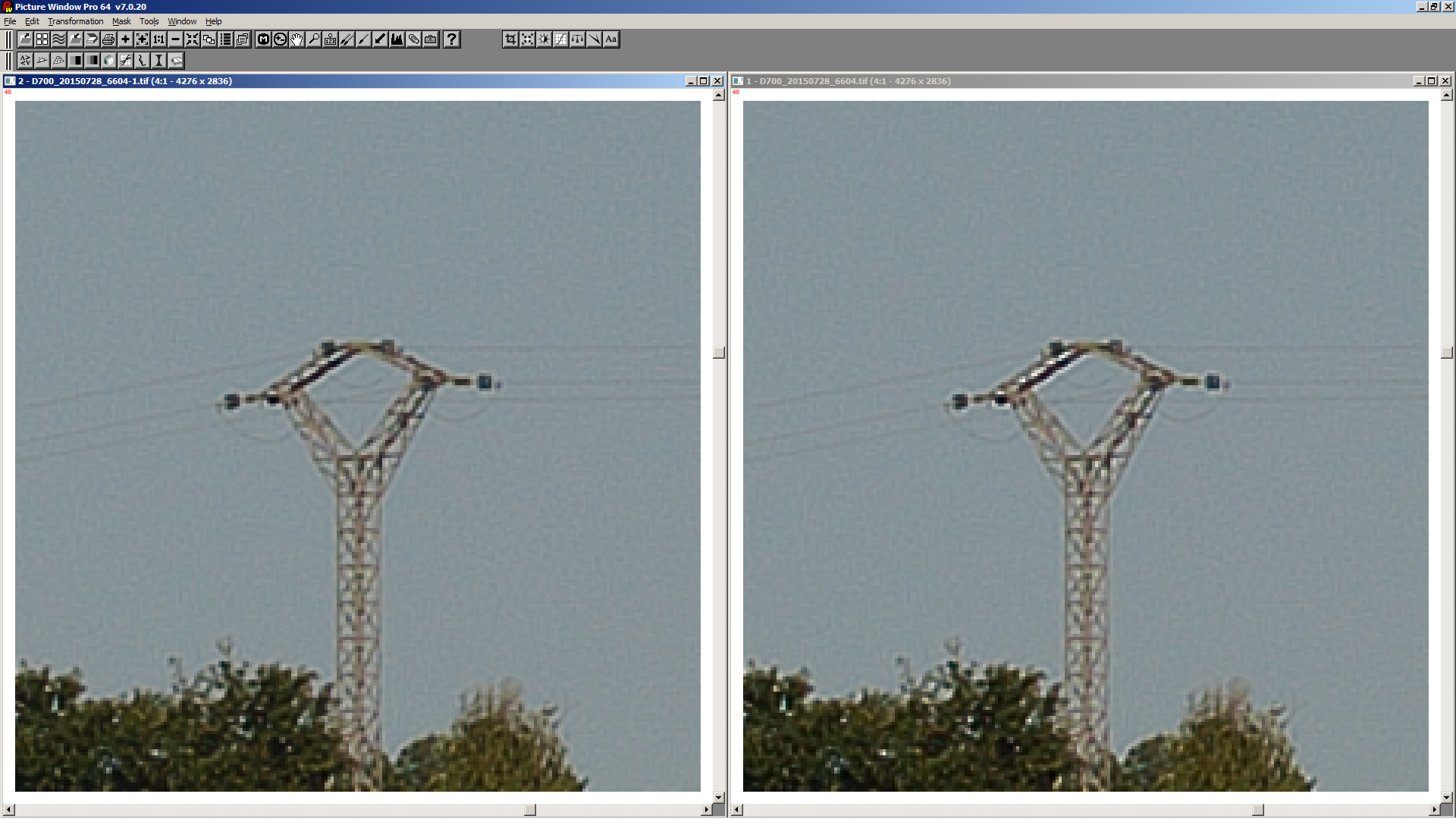
There is a small difference. I could not detect it using the Fuji GFX50R raw file at 100 ISO from the DPReview link, presumably because the file is already quite high resolution.
However, I get the following results using the D7500 file at 800 ISO.



It’s fairly clear the haloing is worse in the first image of each pair. Unsurprisingly, these are the ones following the default RT pipeline. Reversing the order and doing the deconvolution in linear space gives the second image of each pair, with reduced haloing. The tone curve I used is the one from here: Exposure - RawPedia. (I didn’t use auto-curve because the curve would differ between images.)
Relatedly, I would like to raise the idea of decoupling the unsharp mask and deconvolution options. Right now, unless I am missing something, only one can be active at a time. But they do very different things—increasing resolution versus increasing acutance—and it would be very reasonable to want to apply both. Further, I suggest they belong at different stages at the pipline. USM should stay at the end, for the usual reasons. However, deconvolution is essentially “capture sharpening” and compensates for lens diffraction, camera shake, etc., and should be thought of as belonging in the same bucket as lens corrections (distortion correction, CA, etc.) which come early in the pipeline. You could conceivably put it right after the demosaicing with good results, I think.
The same trick (linearizing before applying USM, then delinearizing) reduces haloing in unsharp mask, by the way. So there’s another easy way to improve the sharpening. Examples below were oversharpened to emphasize the effect.
The theoretical explanation is that USM is a linear operation, and so works best in a linear space.
I have to think about how to integrate your method, which clearly has advantages, as you can see in this example (left your method, right standard method), into RT pipeline…
Edit: My example was oversharpenend intentionally
I look forward to seeing what you come up with!
It may also be worth thinking about what other algorithms (e.g. wavelets) would benefit from being done in a linear color space. My guess is most of them, because of how the math works out in their derivations.
You can already do that, though the second sharpening is blind:

I have a quick question myself. If resize is later in the pipeline and post-sharpening after that, how do you make the data linear after nonlinear manipulations? How does RT, dt, PhF, etc., tackle this, respectively?
Not thinking too hard, I can see 2 options: a do all nonlinear operations at the end or b all operations are somehow in linear space; only preview and final output are nonlinear.
I do this in rawproc, but I didn’t specifically set out to do it. rawproc has a processing chain, and it allows selection of any step in the chain to pipe to the display, through the display color/tone transform. So, I can stack a bunch of operators on the base raw image, and select the last one for display. All the operators then just work, in-turn, on the radiometrically linear original data.
But with this great power comes great responsibility… ![]() - the user is responsible for stacking the processing tools in a beneficial order, and there are a lot of orders that are decidedly less-than-beneficial.
- the user is responsible for stacking the processing tools in a beneficial order, and there are a lot of orders that are decidedly less-than-beneficial.
Oh, back to the RL intent of the thread, I’d surmise that, 1) since sharpening is generically an edge-contrast manipulation, and 2) gamma- and other tone transforms definitely mess with contrast. 3) doing any sort of sharpening before the tone transforms will produce outcomes more in line with the sharpening tool’s intent, and less productive of egregious outcomes like haloing. This thinking is making me consider moving my output resize/sharpen steps before any non-linear transforms like filmic…
Imho this thread is about the right place in pipeline for R-L deconvolution, not about linear or non-linear processing in general.
I agree with @nik:
Though also post-resize R-L deconvolution has its use-cases and we also don’t want to break compatibility with older pp3 files. Means, I will add the possibility to apply R-L deconvolution after demosaic. It’s really an improvement.
Here another example (look at the garden hose). Left is old behaviour (Tonecurve before RL, right is RL before Tonecurve, same RL settings for both)
Sorry, which is why I created a new thread right after.
Excellent.
@afre No need to apologize 
There is a fundamental difference between the two approaches which are:
apply RL in linear color space
apply RL at the right step in pipeline
Let me explain:
Applying RL at the end of the pipeline (whatever color space) will apply RL on the transformations done earlier (which in my example is a curve like this (the auto matched tone curve)):

Applying RL before applying the same tone curve results in less haloing. Linear or non-linear processing is not involved here. Just the place in pipeline…
That was what I was saying earlier: later in the pipeline, the data is no longer linear. Could you clarify what you mean by ↓? I think I know but could you elaborate for us?
@afre Sure. I mean that every processing (linear or not-linear) before applying RL changes the input for RL