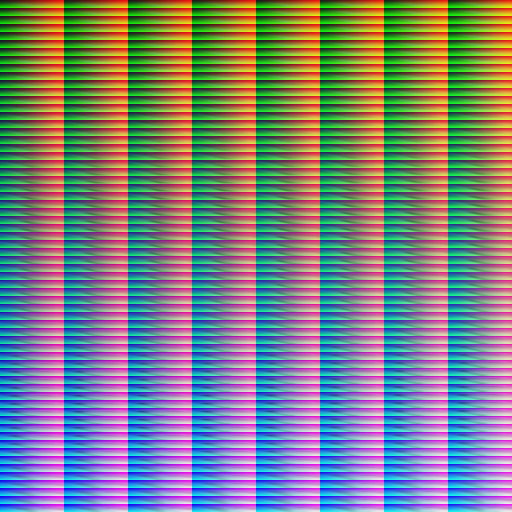
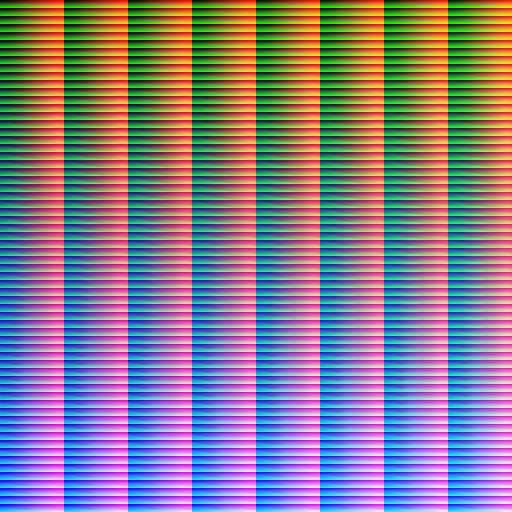
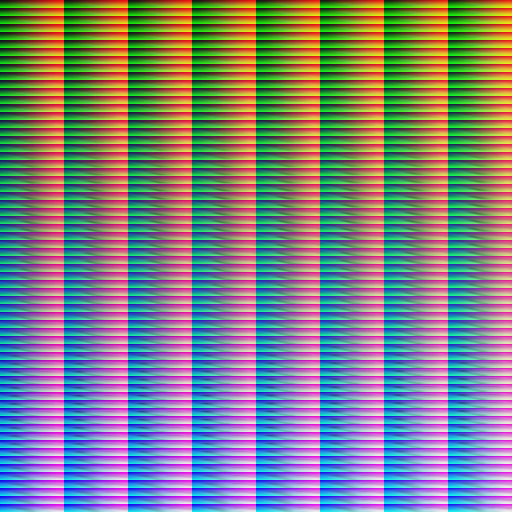
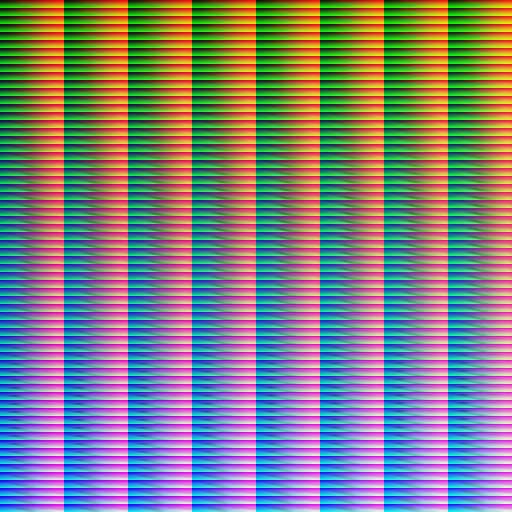
Next, I’ll implement some interpolation and extrapolation and experiment with different kernel sizes/smoothing constants. That should get rid of the graininess that currently plague the LUTs and make them reasonably usable.
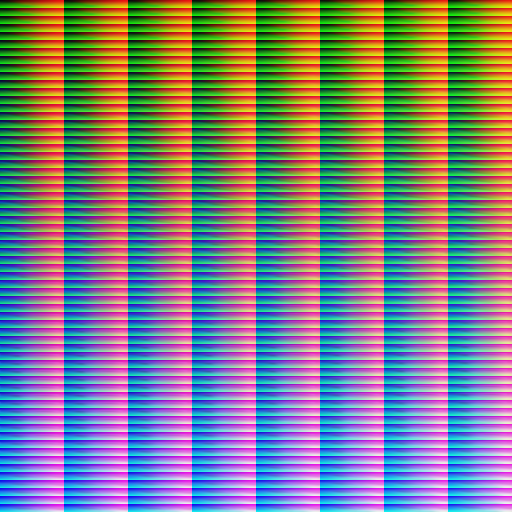
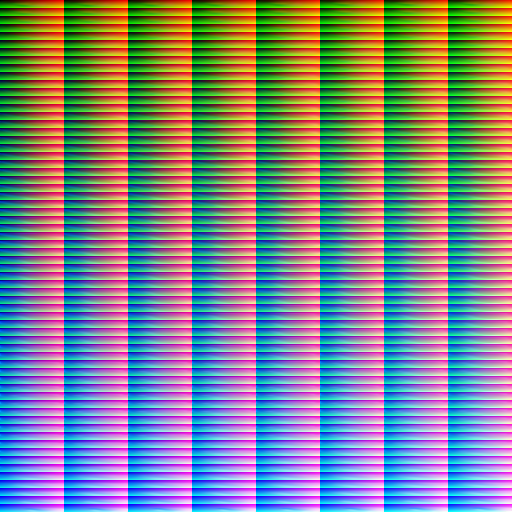
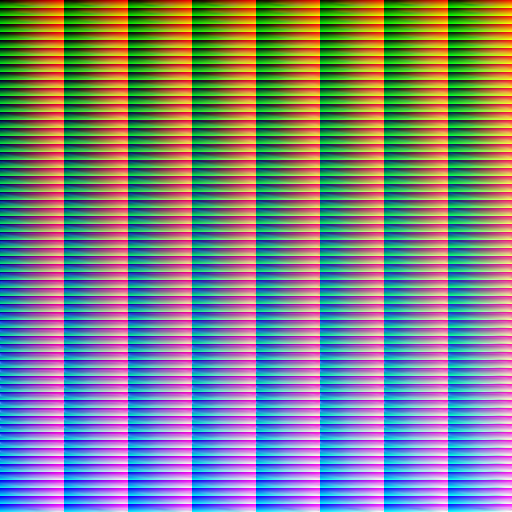
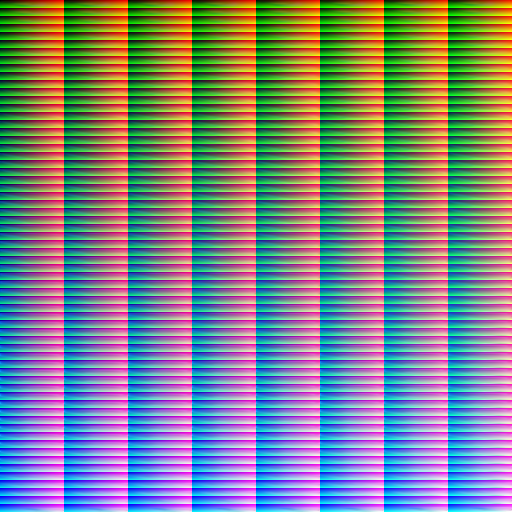
However, the LUTs are currently rather incomplete, especially in the highly saturated parts. That’s simply because the real world is only rarely heavily saturated, so collecting sample images of that is rather hard. The good news is that these colors in fact are rare, so lacking them isn’t a huge issue. And they can be reasonably extrapolated towards from covered colors.
I think collecting more training samples is actually a fool’s errant. Taking sample images is annoying, and I’d always rather spend my time taking useful photographs with real lenses instead. So instead, I’d write an adaptive pixel mapping procedure that should correct for lens distortion and allow me to use my existing library of pictures. This should also fix the need for the extreme subsampling we’re doing at the moment, and make more pixels available per image.
An alternative approach is to manipulate an existing raw file to contain fake data that iterates through all permissible colors. In the end, this might be easier than doing the pixel mapper, and probably more robust as well. And I wouldn’t have to convert hundreds of images to get a reasonable result.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}